 visuals + editorial graphics
visuals + editorial graphicsComplex But Not Dynamic: Using A Static Site To Crowdsource Playgrounds
This post is cross-posted with our friends at Source.

We usually build relatively simple sites with our app template. Our accessible playgrounds project needed to be more complex. We needed to deal with moderated, user-generated data. But we didn’t have to run a server in order to make this site work; we just modified our app template.
Asynchronous Updates
App template-based sites are HTML files rendered from templates and deployed to Amazon’s Simple Storage Service (S3). This technique works tremendously for sites that never change, but our playgrounds site needs to be dynamic.
When someone adds, edits or deletes a playground, we POST to a tiny server running a Flask application. This application appends the update to a file on our server, one line for each change. These updates accumulate throughout the day.
At 5 a.m., a cron job runs that copies and then deletes this file, and then processes updates from the copied file. (This copy-delete-read the copy flow helps us solve race conditions where new updates from the web might attempt to write to a locked-for-reading file. After the initial copy-and-delete step, any new writes will be written to a new updates file that will get processed the next day.)
Each update is processed twice. First, we write the old and new states of the playground to a revision log with a timestamp, like so:
{
'slug': 'ambucs-hub-city-playground-at-maxey-park-lubbock-tx',
'revisions':[
{
'field': 'address',
'from': '26th Street and Nashville Avenue'
'to': '4007 26th Street'
},
],
'type': 'update'
}
Second, we update the playground in a SQLite database. When this is complete, a script on the server regenerates the site from the data in the database. Since each page includes a list of other nearby playgrounds, we need to regenerate every playground page. This process takes 10 or 15 minutes, but it’s asynchronous from the rest of the application, so we don’t mind. We’re guaranteed to have the correct version of each playground page generated every 24 hours.
At each step of the process, we take snapshots of the state of our data. Before running our update process, we time-stamp and copy the JSON file of updates from the previous day. We also time-stamp and copy the SQLite database file and push it up to S3 for safekeeping.
Email As Admin
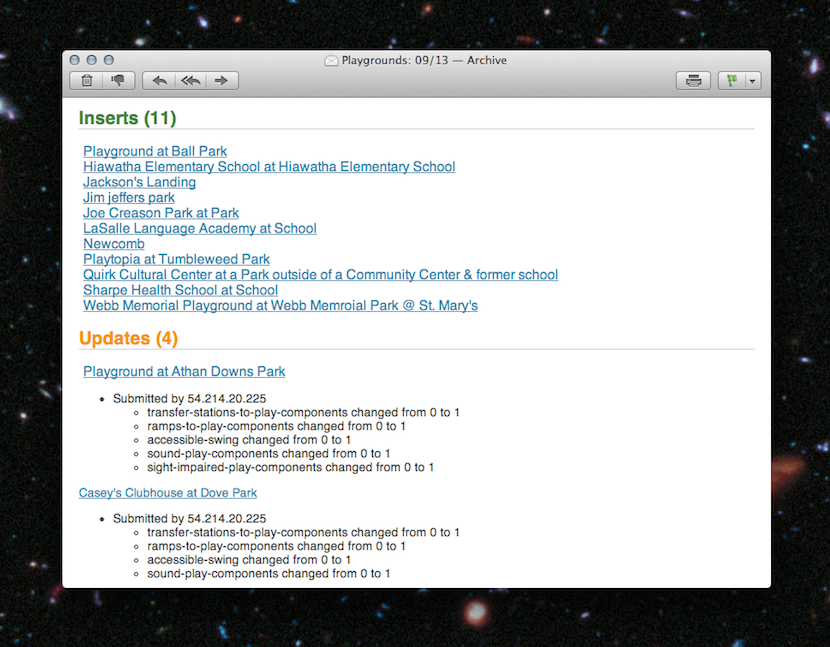
Maintaining a crowdsourced web site requires a little work. We fix spelling and location errors, remove duplicates, and delete playgrounds that were added but aren’t accessible.
Typically, you’d run an admin site for your maintenance tasks, but we decided that our editors use the public-facing site just like our readers. That said, our editors still need a way to check the updates our users are making.
Since we only process updates once every 24 hours, we decided to just send an email. For additions, we link the playground URL in the email so that editors could click through. For updates, we list the changes. And for delete requests, we include a link that, when clicked, confirms a deletion and instructs the site to process the delete during the next day’s cron.
Search
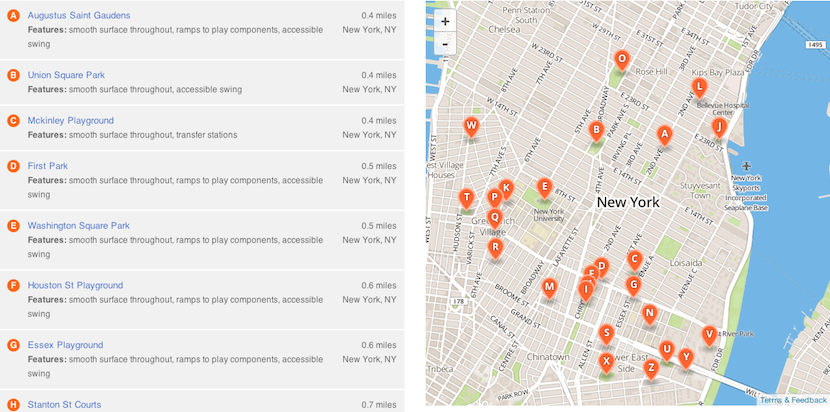
Flat files are awesome, but without a web server, how do you search?
To solve this, we use Amazon’s CloudSearch. Eventually, we’ll probably implement a way to find playgrounds with certain features or to search by name. But right now, we’re using it just for geographic search, e.g., finding playgrounds near a point.
To implement geographic search in CloudSearch you need to use rank expressions, bits of JavaScript that apply an order to the results. CloudSearch allows you to specify a rank expression as a parameter to the search URL. That’s right: Our search URLs include a string that contains instructions for CloudSearch to order the results. Amazon has documentation on how to use this to implement simple “great circle” math. We took it a step further and implemented spherical law of cosines because it is a more accurate algorithm for determining distance between points on a sphere.
You can see the source code where we build our search querystrings in the playgrounds repository, but you should take note of a few further caveats.
CloudSearch only supports unsigned integers, so we have to add the 180 degrees (because latitudes and longitudes can be negative numbers) and also multiply the coordinates by 10,000 (because an unsigned integer can’t have a decimal point) to get five decimal points of precision. Finally, we have to reverse this process within our rank expression before converting the coordinates to radians to calculate distance.
Also, a single CloudSearch instance is not very stable when running high-CPU queries like geographic searches. During load testing we saw a large number of HTTP 507 errors, indicating that the search service was overloaded. Unfortunately, 5xx errors and JSONP don’t mix. To solve this, we catch 507 errors in Nginx and instead return a HTTP 202 with a custom JSON error document. The 202 response allowed us to read the JSON in the response and then retry the search if it failed. We retry up to three times, though in practice we observed that almost every failed request would return a proper result after only a single fail/retry.
Finally, while Amazon would auto-scale our CloudSearch instances to match demand, we couldn’t find any published material explaining how often Amazon would spin up new servers or how many would initialize at once. So, we reached out to Amazon. They were able to set our CloudSearch domain to always have at least two servers at all times. With the extra firepower and our retry solution, on launch day we had no problems at all.
Retrofitting CloudSearch For JSONP
You might notice we’re doing all of our CloudSearch interaction on the client. But the CloudSearch API doesn’t support JSONP natively. So we need to proxy the responses with Nginx.
Option 1: CORS
We could have modified the headers coming back from our CloudSearch to support Cross-Origin Resource Sharing, aka CORS. CORS works when your response contains a header like Access-Control-Allow-Origin: *, which would instruct a Web browser to trust responses from any origin.
However, while CORS has support in many modern browsers, it fails in older versions of Android and iOS Safari, as well as having inconsistent support in IE8 and IE9. JSONP just matched our needs more closely than CORS did.
Option 2: Rewrite the response.
Once we settled on JSONP, we knew we would need to rewrite the response to wrap it in a function. Initially, we specified a static callback name in jQuery and hard-coded it into our Nginx configuration.
This pattern worked great until we needed to get search results twice on the same page load. In that case, we returned a function with new data but with the same function name as the previous AJAX call. The result? We didn’t see any updated data. We needed a dynamic callback where the function that wraps your JSON was unique for each request. jQuery will do this automatically.
Now we needed our Nginx configuration to sniff the callback out of the URL and then wrap it around the response. And while this might be easy using some nonstandard Nginx libraries like OpenResty, we didn’t have the option to recompile our Nginx on the fly without possibly disturbing existing running projects.
One other hassle: Amazon’s CloudSearch would return a 403 if we included a callback param in the URL. Adding insult to injury, we’d need to strip this parameter from the URL before proxying it to Amazon’s servers.
Thankfully, Nginx’s location pattern-matcher allowed us to use regular expressions with multiple capture groups. Here’s the final Nginx configuration we used to both capture and strip the callback from the proxy URL.
Nginx Proxy And DNS
Another thing you might notice: We had to specify a DNS server in the Nginx configuration so that we could resolve the domain name for the Amazon CloudSearch servers. Nginx’s proxy_pass is meant to work with routable IP addresses, not fully-qualified domain names. Adding a resolver directive meant that Nginx could look up the DNS name for our CloudSearch server instead of forcing us to hard-code an IP address that might change in the future.
Embrace Constraints
Static sites with asynchronous architectures stay up under great load, cost very little to deploy, and have low maintenance burden.
We really like doing things this way. If you’re feeling inspired, complete instructions for getting this code up and running on your machine are available on our GitHub page. Don’t hesitate to send us a note with any questions.
Happy hacking!


